Adaptive Token Sampling for Efficient Vision Transformers
(ECCV Oral)

* denotes equal contribution.
Method

(ECCV Oral)
* denotes equal contribution.
Method
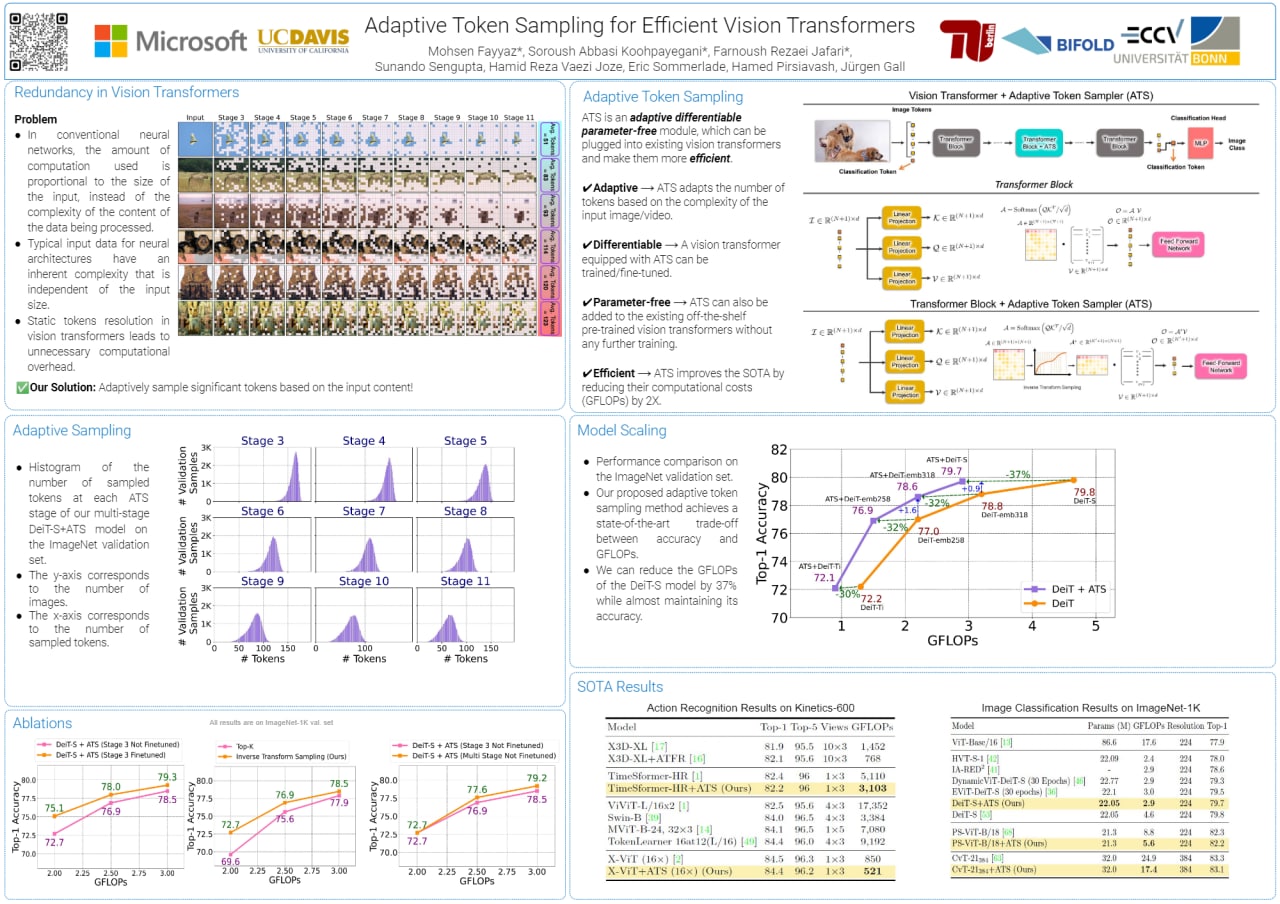
|
 |
@inproceedings{ATS,
title = {Adaptive Token Sampling for Efficient Vision Transformers},
author = {Mohsen Fayyaz and Soroush Abbasi Koohpayegani and Farnoush Rezaei Jafari and Sunando Sengupta and Hamid Reza Vaezi Joze and Eric Sommerlade and Hamed Pirsiavash and Juergen Gall},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2022}
}